
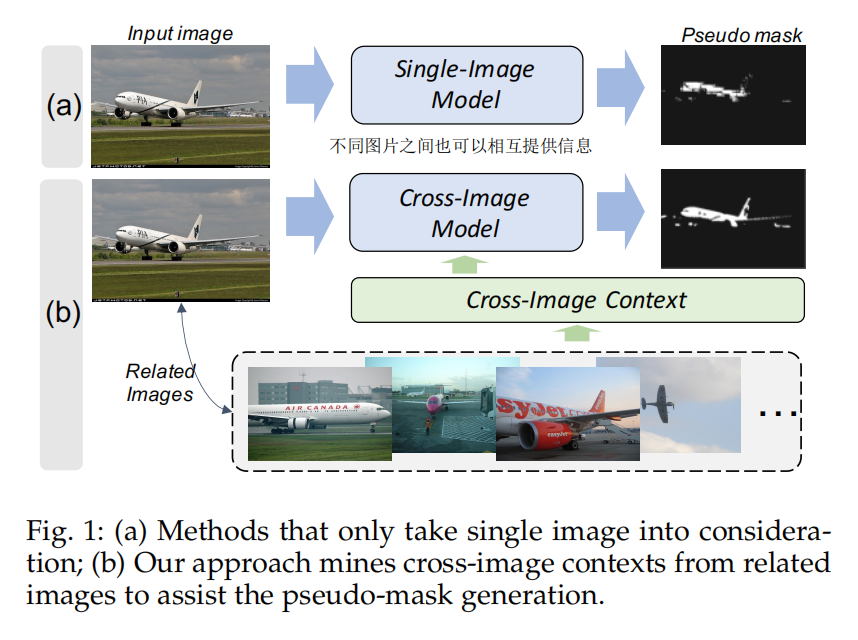
本文主要的贡献在于利用上了不同图片之间的信息进行semi-supervised segmentation(image-level label),并没有着重强调如何生成伪标签。
Classification Module
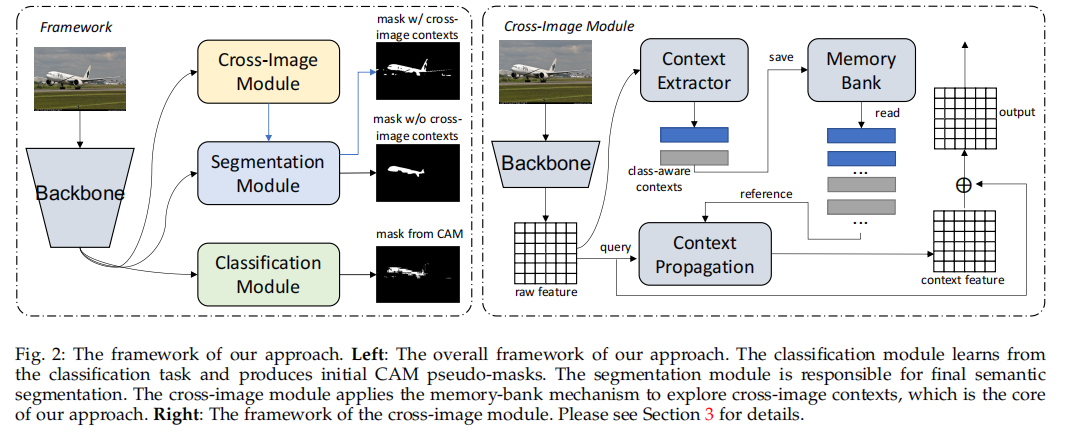
首先将backbone的encoder的输出$f=B(I;\theta_b)\in \R^{d\times HW}$放入图中的Classification Module中,生成dense heatmap $h\in \R^{L\times HW}$,$L$是类别数。
训练
作者这里在生成CAM的这一支,将最后一层改为conv1x1,并且扔掉了GAP改为在spatial上做平均,得到cls logit $\bar h\in \R^L$
loss就是交叉熵:

其中$\sigma$是sigmoid。
Pseudo Mask
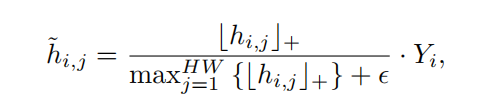
$\lfloor \cdot \rfloor_+$表示向下取整。需要注意的是,监督信号$L_{seg}$不仅需要object的mask还要有背景的mask。作者这里follow了以往的做法,使用无监督的方法,提取显著性图,以此得到背景$h_{bg}$,最后与$\tilde h$ cat起来,所以$\tilde h\in \R^{(L+1) \times HW}$,这里乘$Y_i$是为了将没有在该图片中出现的类别滤除,避免引入噪声,特别是在训练的初期。
由此得到pseudo mask $M \in \R^{HW}$,卡一个阈值:
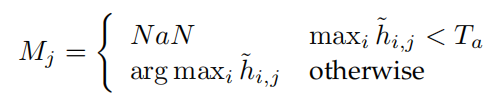
Memory based Cross-Image Context Provider
Context Extractor
首先cross-image context应该和query的类别一致,所以Context Extractor应该是class-wise的。
给定feature $f\in \R^{d\times HW}$,第$k$类cross-image context为:
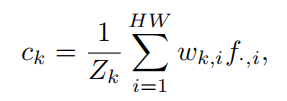
$w_{k,i}$是融合权重,其应该与第$i$个像素对应第$k$个类别的自信度有关(越自信的像素占有的权重就越大,当然前提是这个像素是正确的自信),那么将其定义为(也是卡一个阈值,让不自信的像素不参与传播):
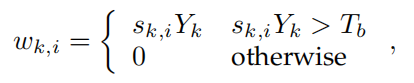
$s\in \R^{(L+1)\times HW}$是从segmentation module预测的每个类别的自信度。那么可以看出对于每张图片来说,其含有的类别是不同的(有可能有多个类别),所以$k$是不同的。
Memory Bank
实现上就是一个队列,大小为$N\times (L+1)$,每次取与query相同类别的pixel feature:
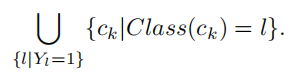
Cross-Image Context Propagation Module
本文的创新点主要就在这一点,将不同图片相同类别里的object相互计算attention,得到cross-image pseudo mask。
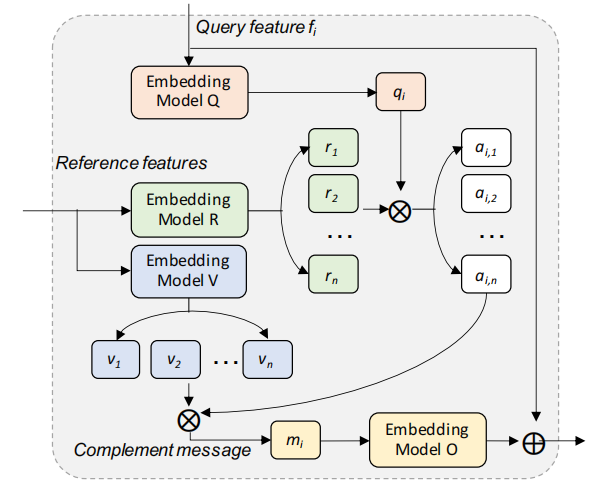
输入$q$是经过backbone的raw feature,输入$r,v$都是经过backbone和context extractor的其他图片。
接下来就是attention操作:
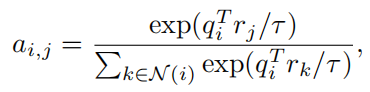
这里的下标代表位置$i,j\in {1, \dots, HW}$,最理想的情况是query对于reference提取出有用且互补的信息,而不是简单地将reference的所有信息取平均($a_{i,j}=1/N, N=HW$),所以需要在此加上限制,以保证sparsity:
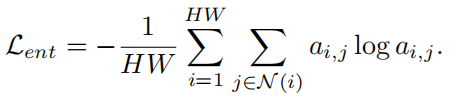
那么如何传播呢?很简单,将$a$与$v$相乘就好:
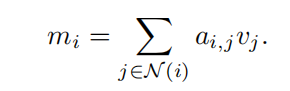
再将其映射回feature space:
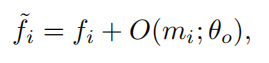
这样得到的feature就是有其他图片相同类别信息的feature了。
那么feature改变了,pseudo mask也要发生变化,如前述,将feature $\tilde f$输入到Classification Module中,得到dense heatmap $\hat h\in \R^{(L+1)\times HW}$,再利用下式得到新的pseudo mask $M^\prime$:
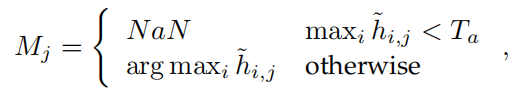
再将增强之后的pseudo mask和CAM mask融合起来:
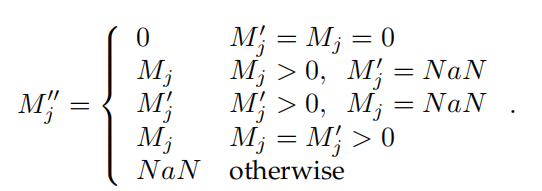
实际上就是使用了其他相同类别的object的信息隐式地将pseudo mask扩大了。
Segmentation Module
这个模块的预测值$s=S(f;\theta_s)\in \R^{(L+1)\times HW}$,实际实现就是几层卷积层,输出大小与输入大小一直。
loss为:
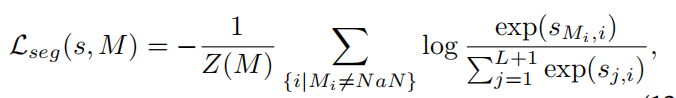
$Z(M)$为归一化因子,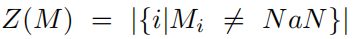 ,$NaN$的像素不参与计算。
,$NaN$的像素不参与计算。
训练流程
总的loss如下:
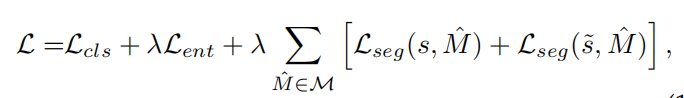
在训练的早期,得到的pseudo mask不够准确,$\lambda$需要使用一个小的值,到了训练后期,$\lambda$可以使用一个较大的值。作者这里选取了多项式的warm up策略:
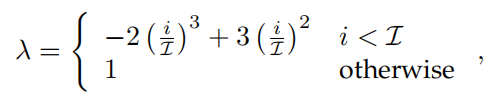
$\mathcal I$是一个预先设定好的epoch值。
其他细节
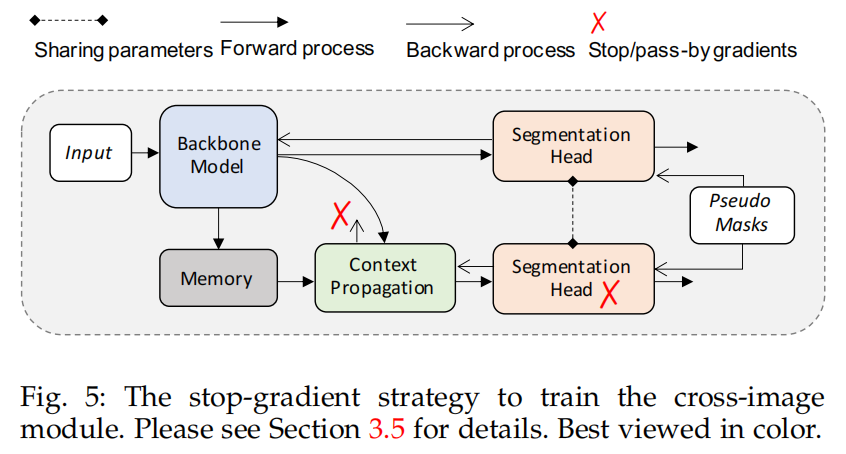
在测试的时候segmentation module不能得到cross-image context,作者这里使用了stop gradient用来弥补这个gap,也就是说cross-image feature的梯度不会传递到segmentation module,只用来更新context propagation module。