

介绍视频:CVPR2022 XMP-Font 哔哩哔哩_bilibili
paper:https://arxiv.org/abs/2204.05084
学那么多理论,还是需要看下在工业界是咋用的,以及对应的task有什么trick。
总的来说,这篇文章写作一般,没有很清楚地交代背景,如果不是中国人很难读懂为什么这样设计,并且在method部分的有些描述与给出图不符合。另外要吐槽的是,短短10页,pdf文件500多M,不知道里面放了啥。
这一篇中了CVPR2022。还有一篇做同样任务的投了ICRL22被拒了。
简介
作者设计了一个自监督预训练方法和一个跨域的依赖于字符图像和对应笔画的表情的encoder(transformer-based),可以在few-shot的情况下,生成质量很好的中文字体。
方法
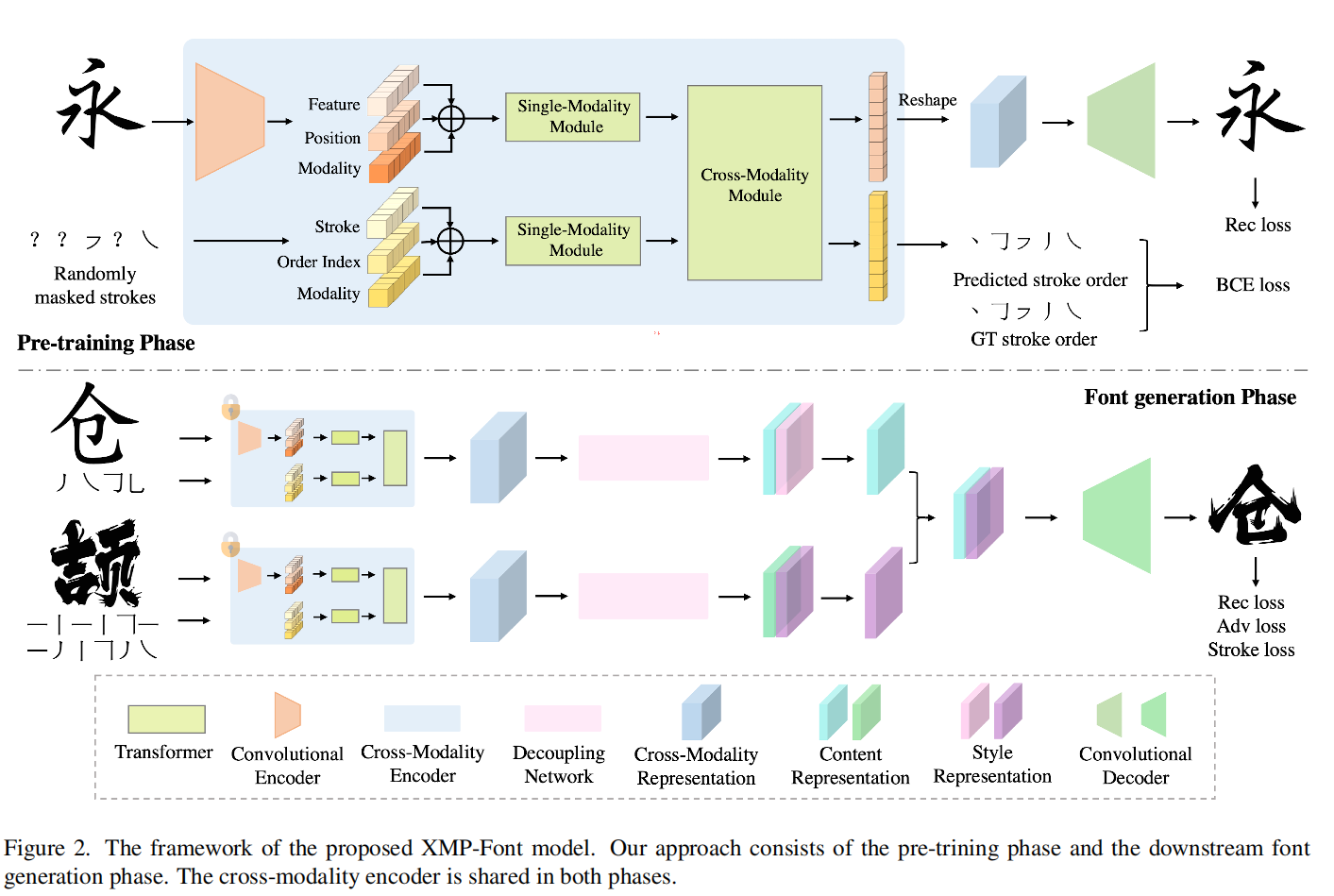
阶段一 跨域的encoder
输入分别是两个模态,一个是字形,一个是随机mask的笔画。字形被embed成三部分,分别是feature、position和一个指示模态的indicator(文中写为modality);笔画也被embed成三部分,分别为stoke、order index和modality。
对于笔画来说,28个笔画就足以构成常用的中文字体,所以每个笔画会对应有一个label,这样经过embedding layer之后就成为512维的stroke label embedding。在构成一个字的时候,每个笔画是有顺序的(从上到下,从左到右),所以对应笔画的顺序会有一个order index embedding。剩下的modality embedding为了指示是哪一个模态。
对于字形来说,输入为$256\times 256\times 3$的图像,经过5层卷积层之后成为$8\times8\times 512$的feature map,被展成$64\times 512$的embedding。position embedding是从x-y平面得到,其实就是Transformer中的pe。
作者也指出位置信息是必须的,因为后续的transformer layer需要。
self- and cross-attention layer
对于单模态的module,作者使用9个BERT layer处理笔画信息,5个BERT layer处理字形信息。
对于cross-modality module,组成情况有些复杂,主要作用就是为了在两个模态中交互信息,在这里不做过多介绍。
预训练方法
为了得到字形图像和相关笔画的交互信息,作者在一个大的字体数据集上进行了预训练。
仿照BERT的训练方式,有0.375的概率所有的笔画都被mask,在剩余的情况中,每个笔画有0.5的概率被mask。对于没有mask的stroke embedding,直接算出对应的笔画的概率,计算一个CE loss;对于被mask的masked stroke embedding,会被没有mask的笔画所预测,当然也可以被字形信息所预测,作者将其称之为stroke reconstruction task。
对于字形信息,在encoder之后接卷积层将embedding重建为输入的字形即可,loss是L1 loss。